Microbenchmarks: BlockingQueues vs LMAX Disruptor
BlockingQueue is one of the Java abstractions that I use more than anything else. They are built into the JVM, so I don’t need to get any special approval to use them, I don’t like working with locks, and I find that a message-passing style lends itself much better to concurrent programming than mutexes. It doesn’t help that I’m not smart enough to use mutexes correctly. BlockingQueues have generally been fine, but in a recent project, I managed to push them a bit beyond their limit.
This project had about sixty threads all writing to the queue all at once. This technically “works”, as in there’s no limit to how many threads can write to a BlockingQueue at the same time, but you risk very strong latency spikes due to lock contention. This is exactly what happened, and it dramatically reduced the throughput of my application by a lot, upwards of forty percent in some cases.
This led to me looking into alternatives to BlockingQueues that offer similar guarantees but handle things more efficiently, and that’s how I stumbled upon LMAX Disruptor. Blah
LMAX Disruptor
In a nutshell, LMAX Disruptor is a concurrency framework for Java. It offers a queue abstraction, not dissimilar from BlockingQueues. It gives you the option to block on the put when the queue is full, but its internal constructs give you a lot more configurabilty. For example, instead of having it use a regular Lock to handle the queue being full, you can have it spinwait until something is ready.
Why do they do this? Simple, Disruptor’s main goal, arguably its only goal, is to minimize latency. Why would you want a spinwait? Because that avoids a context switch, and context switches increase latency.
It’s all over their design. Your queue can only be sized as an exponent of $2$ so that it can use a bitmask instead of a modulus, because modulus takes multiple cycles and bitmasking takes one. They use a ring buffer because ring buffers don’t generate garbage, and the less garbage means fewer garbage collection cycles, and garbage collection cycles cause latency. Locks aren’t really used, instead relying on the use of Compare and Swap, which generally has lower contention and therefore lower latency.
This design, apparently, leads to LMAX going cartoonishly fast, while also giving a relatively straightforward interface. It sounds amazing, and it probably is, but if I want to use it and rewrite my code to take advantage of it, I want some concrete numbers. LMAX themselves has numbers, but I still would like to run it on my own hardware to get an idea of how it will compare locally. I have trust issues.
I decided to write some JMH tests just to get some basic back-of-napkin numbers to see how much trhoughput I can get. I figure if Disruptor is considerably faster, it will be an easier sell my coworkers on it, and if it’s not much faster, I don’t really need to bother changing to it. I also think that JMH is fun to play with, so why the hell not?
My Benchmark
My benchmark is as follows:
package org.jmh;
import java.util.UUID;
public class UUIDWrapper {
public UUID theUUID;
public void setTheUUID(UUID x) {
theUUID = x;
}
}
package org.jmh;
import com.google.common.collect.Lists;
import com.lmax.disruptor.SleepingWaitStrategy;
import com.lmax.disruptor.dsl.Disruptor;
import com.lmax.disruptor.dsl.ProducerType;
import org.openjdk.jmh.annotations.*;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
public class JMHWrapper3
{
@State(Scope.Benchmark)
public static class SharedData {
List<UUID> keys;
@Param({"100", "1000", "10000"})
public int numInsertions;
@Param({ "128", "256", "512", "1024"})
public int queueSize;
@Param({ "4", "8", "16", "32"})
public int numThreads;
@Setup(Level.Trial)
public void setup() {
keys = IntStream.range(0, numInsertions)
.mapToObj(i -> UUID.randomUUID())
.collect(Collectors.toList());
}
}
@State(Scope.Thread)
public static class MapState {
public CountDownLatch singleDisruptorLatch;
public CountDownLatch multiDisruptorLatch;
public Disruptor<UUIDWrapper> multiDisruptor;
public Disruptor<UUIDWrapper> singleDisruptor;
public BlockingQueue<UUID> arrayBlockingQueue;
public BlockingQueue<UUID> linkedBlockingQueue;
public CountDownLatch queueLatch;
@Setup(Level.Iteration)
public void setup(SharedData sharedData) {
arrayBlockingQueue = new ArrayBlockingQueue<>(sharedData.queueSize);
singleDisruptorLatch = new CountDownLatch(sharedData.numInsertions);
multiDisruptorLatch = new CountDownLatch(sharedData.numInsertions);
queueLatch = new CountDownLatch(sharedData.numInsertions);
singleDisruptor = new Disruptor<>(UUIDWrapper::new, sharedData.queueSize,
Executors.defaultThreadFactory(), ProducerType.SINGLE, new SleepingWaitStrategy());
multiDisruptor = new Disruptor<>(UUIDWrapper::new, sharedData.queueSize,
Executors.defaultThreadFactory(), ProducerType.MULTI, new SleepingWaitStrategy());
singleDisruptor.handleEventsWith((event, sequence, endOfBatch) -> {
// System.out.println("Test");
singleDisruptorLatch.countDown();
});
multiDisruptor.handleEventsWith((event, sequence, endOfBatch) -> {
multiDisruptorLatch.countDown();
// System.out.println(multiDisruptorLatch.getCount());
});
singleDisruptor.start();
multiDisruptor.start();
}
@TearDown(Level.Iteration)
public void teardown() {
if (singleDisruptor != null) {
singleDisruptor.shutdown();
}
if (multiDisruptor != null) {
multiDisruptor.shutdown();
}
}
}
@Benchmark
public void disruptorThroughputSingleProducer(MapState state, SharedData data) throws InterruptedException {
// state.singleDisruptor.start();
try (var executorService = Executors.newFixedThreadPool(data.numThreads)) {
var rb = state.singleDisruptor.getRingBuffer();
executorService.submit(() -> {
data.keys.forEach(i -> {
var n = rb.next();
try {
rb.get(n).setTheUUID(i);
} finally {
rb.publish(n);
}
});
});
state.singleDisruptorLatch.await();
}
}
@Benchmark
public void disruptorThroughputMultiProducer(MapState state, SharedData data) throws InterruptedException {
try (var executor = Executors.newFixedThreadPool(data.numThreads)) {
var rb = state.multiDisruptor.getRingBuffer();
Lists.partition(data.keys, data.numInsertions / (data.numThreads )).forEach(j -> {
executor.submit(() -> {
j.forEach(i -> {
// System.out.println("Howdy");
var n = rb.next();
try {
rb.get(n).setTheUUID(i);
} finally {
rb.publish(n);
}
});
});
});
state.multiDisruptorLatch.await();
}
}
@Benchmark
public void blockingQueueThroughputSingleProducer(MapState state, SharedData data) throws InterruptedException {
try (var executorService = Executors.newFixedThreadPool(data.numThreads)) {
executorService.submit(() -> {
for (UUID key : data.keys) {
try {
var item = state.arrayBlockingQueue.take();
long remaining = state.queueLatch.getCount();
state.queueLatch.countDown();
if (remaining == 1) { // Stop when last element is processed
break;
}
} catch (InterruptedException ignored) {
}
}
});
try {
for (UUID key : data.keys) {
state.arrayBlockingQueue.put(key);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
state.queueLatch.await();
}
}
@Benchmark
public void blockingQueueThroughputMultiProducer(MapState state, SharedData data) throws InterruptedException {
try (ExecutorService executor = Executors.newFixedThreadPool(data.numThreads)) {
executor.submit(() -> {
for (UUID _key : data.keys) {
try {
var item = state.arrayBlockingQueue.take();
long remaining = state.queueLatch.getCount();
state.queueLatch.countDown();
if (remaining == 1) { // Stop when last element is processed
break;
}
} catch (InterruptedException ignored) {
}
}
});
Lists.partition(data.keys, data.numInsertions / (data.numThreads)).forEach(j -> {
executor.submit(() -> {
try {
for (UUID key : j) {
state.arrayBlockingQueue.put(key);
}
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
});
});
state.queueLatch.await();
}
}
}
I don’t know the CountDownLatch is the correct thing to use for synchronization, but due to the fact that Disruptor is callback-based, I couldn’t really think of a way to force JMH to block until the test is done. Disruptor should be running primarily in its own thread, so I don’t think I’m adding a lot of blocking, but if anyone has a better idea I’m happy to hear it.
I had trouble getting the @Threads parameter working for this correctly, so for now I’m just using ExecutorService to handle creating, dispatching, and cleaning up of threads. It seemed to work, agan if I’m doing something dumb please tell me.
I wanted to see how the queue size and the number of threads affected throughput, in addition to the more obvious number of messages. The queue size, in particular, is extremely valuable; if we can get away with a smaller queue, that can be considerably less memory. My intuition tells me that a bigger queue size should be faster, but I’ve never tested it.
Adding all these parameters creates a combinatorial mess; we need to run $3 \cdot 4 \cdot 4 \cdot 4$ number of tests to run, with five iterations each. These numbers are huge, but I think they’re necessary to get realistic number
This test took an entire day to to run, so I didn’t want to run it on my laptop, so I copied it over to my server. As usual, computer specs will be on the bottom of this post.
The amount of data is a bit too huge to dump onto this page, but feel free to look at the CSV. Load it into Excel or Pandas or something and see if you can find something interesting, and let me know.
I’m not great at data visualizations, but I was able to coerce ChatGPT to aggregate this for me, so here are some pretty graphs.
Let’s start with the single producer ones:
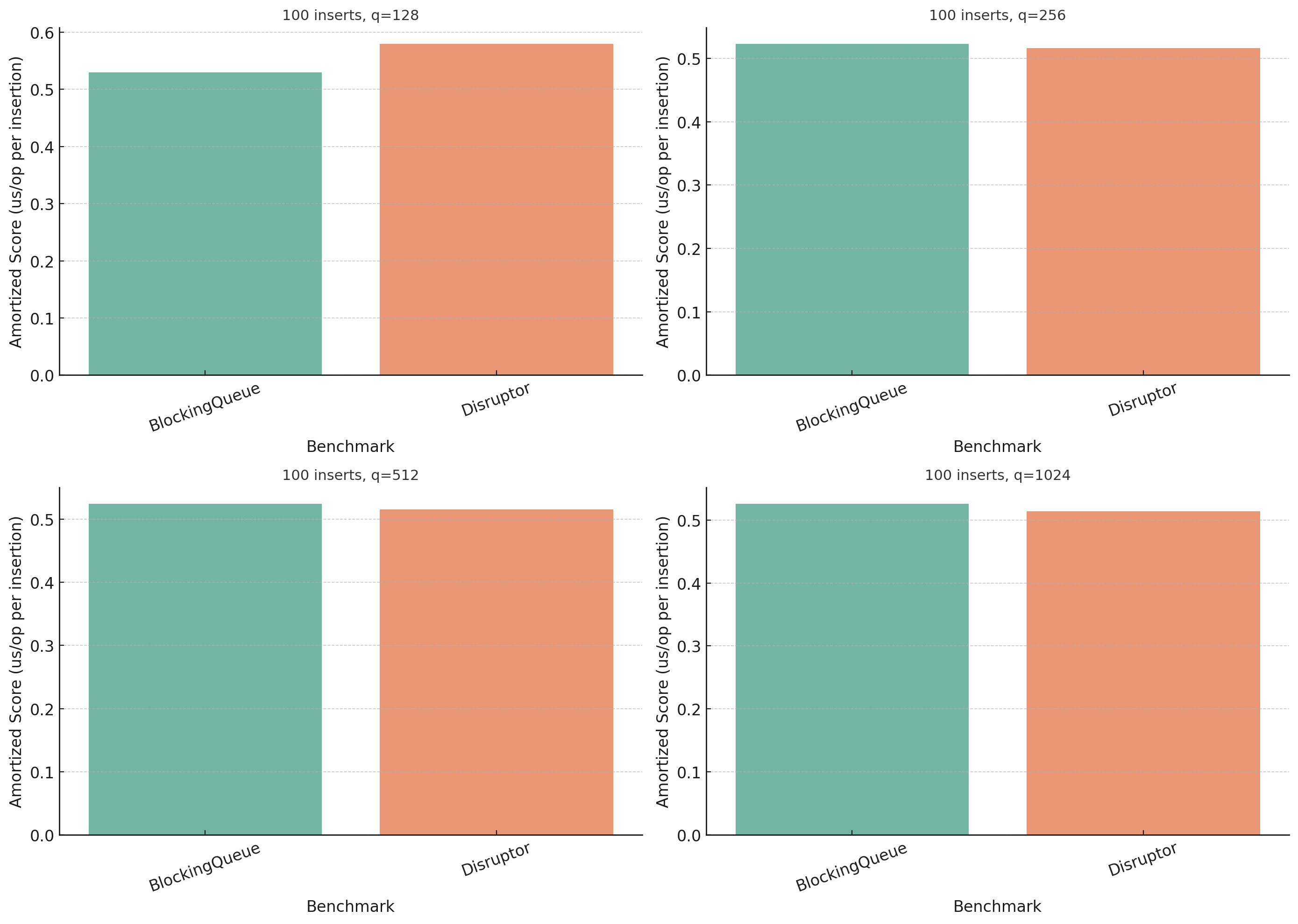

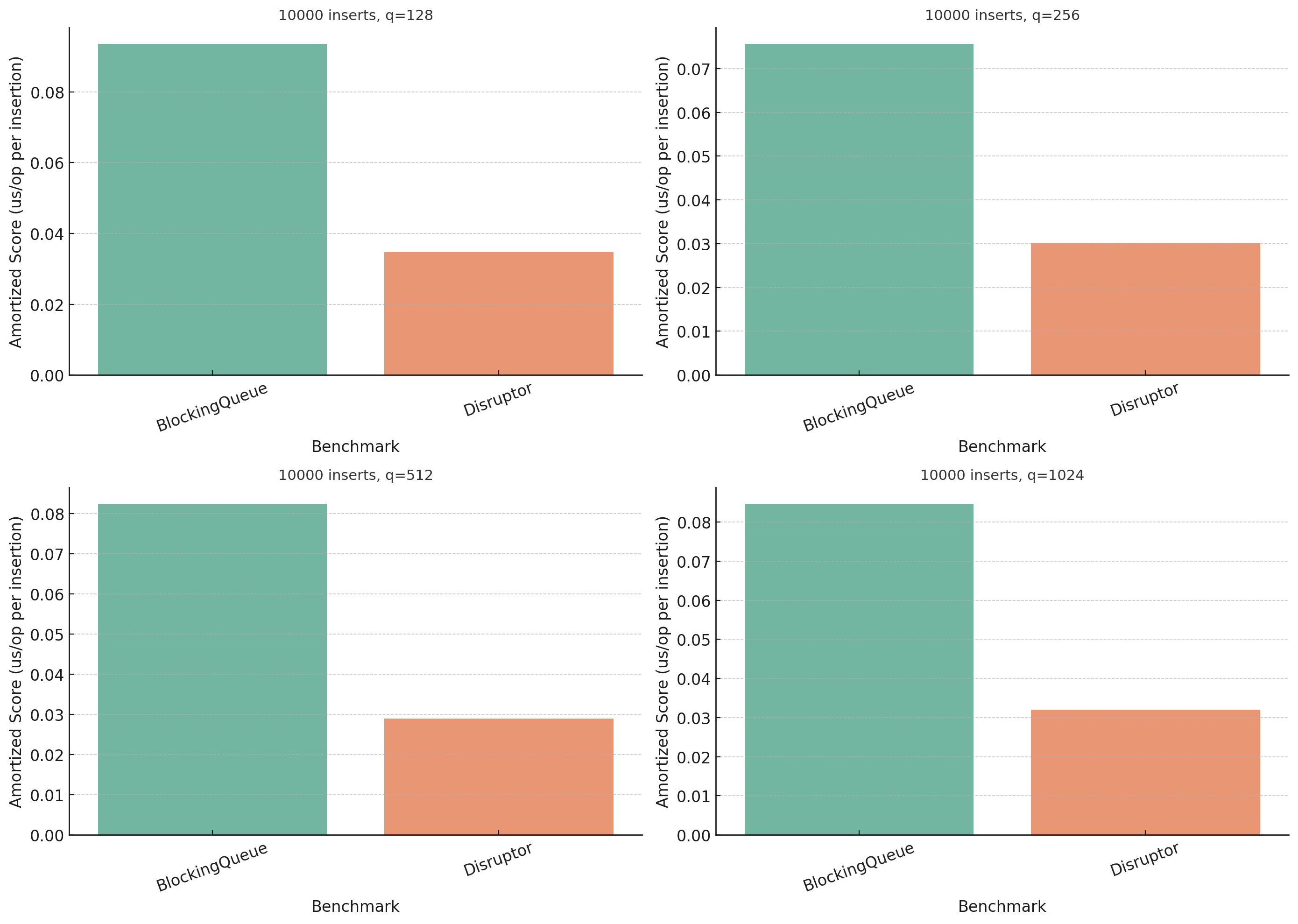
The results weren’t as dramatic as I hoped, at least not until the end. It seems like Disruptor is roughly twice the speed of BlockingQueue once we get enough data in there to be interesting. I need to run the tests again with a bigger batch size.
Now let’s look at the multi producer tests. This is microseconds per operation. Lower is better:
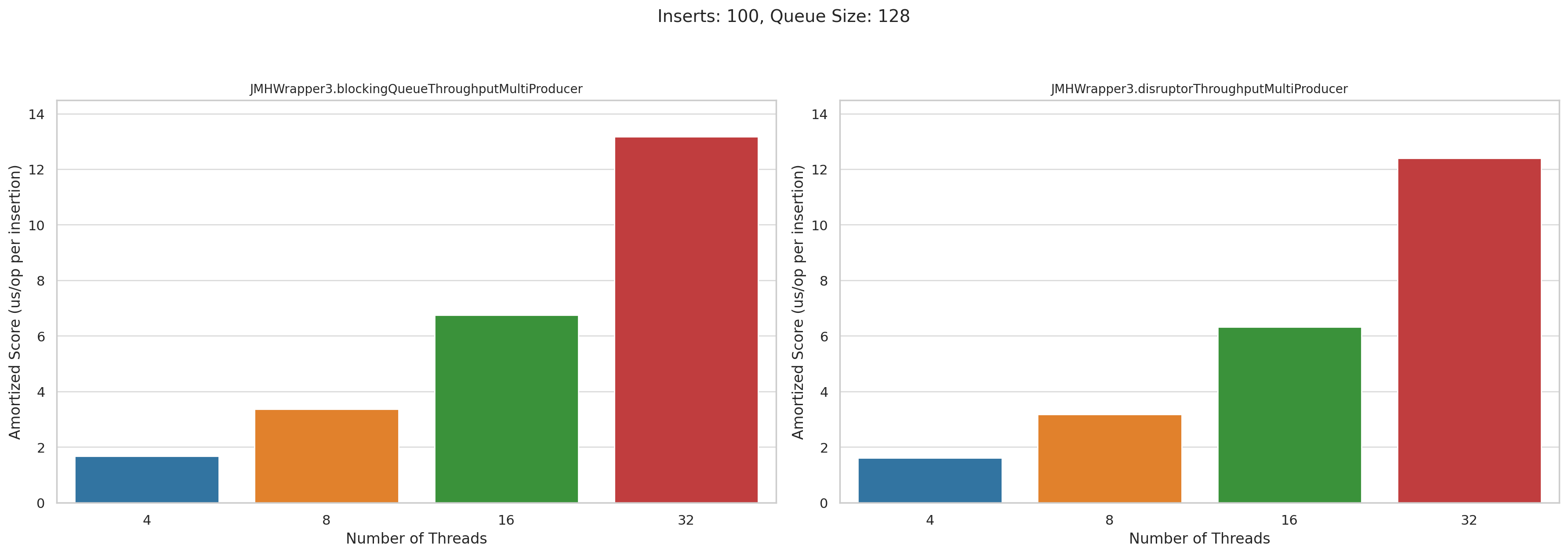

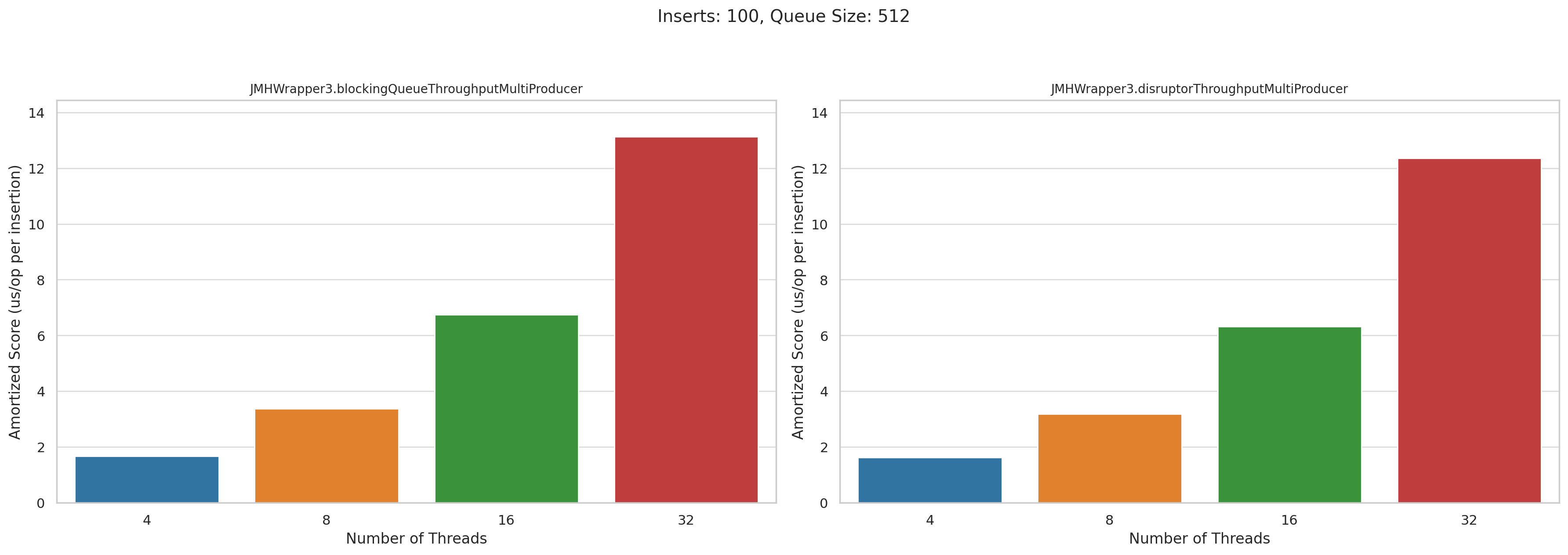
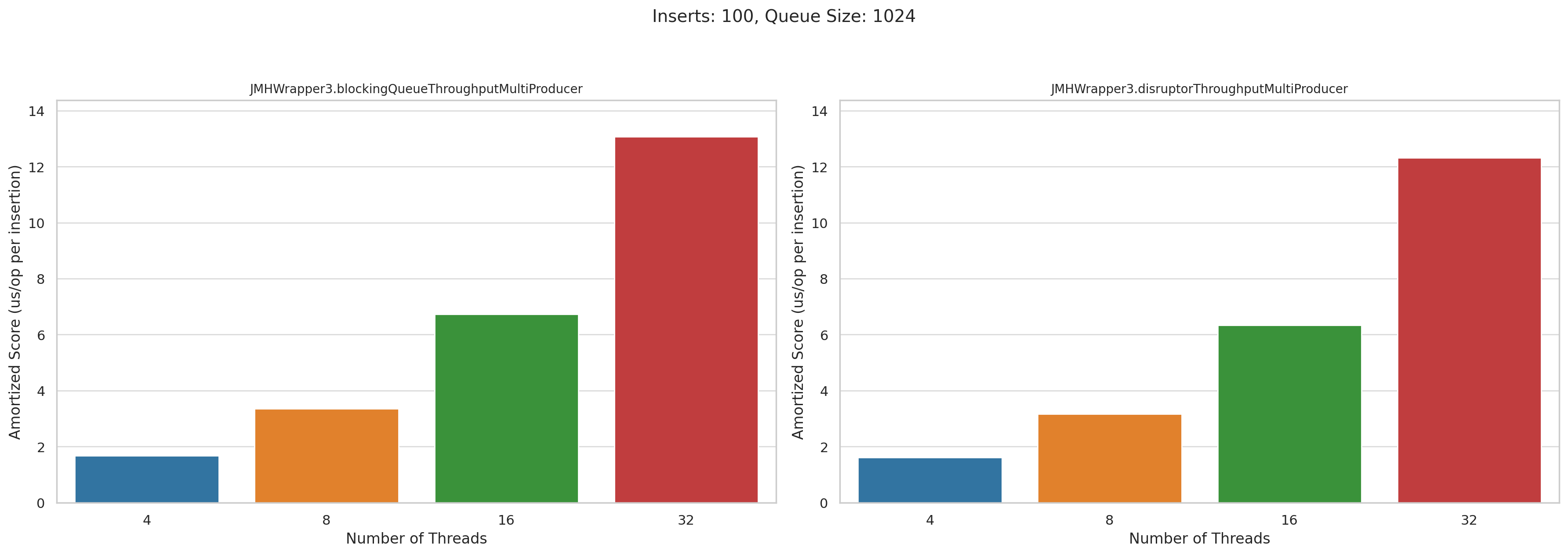
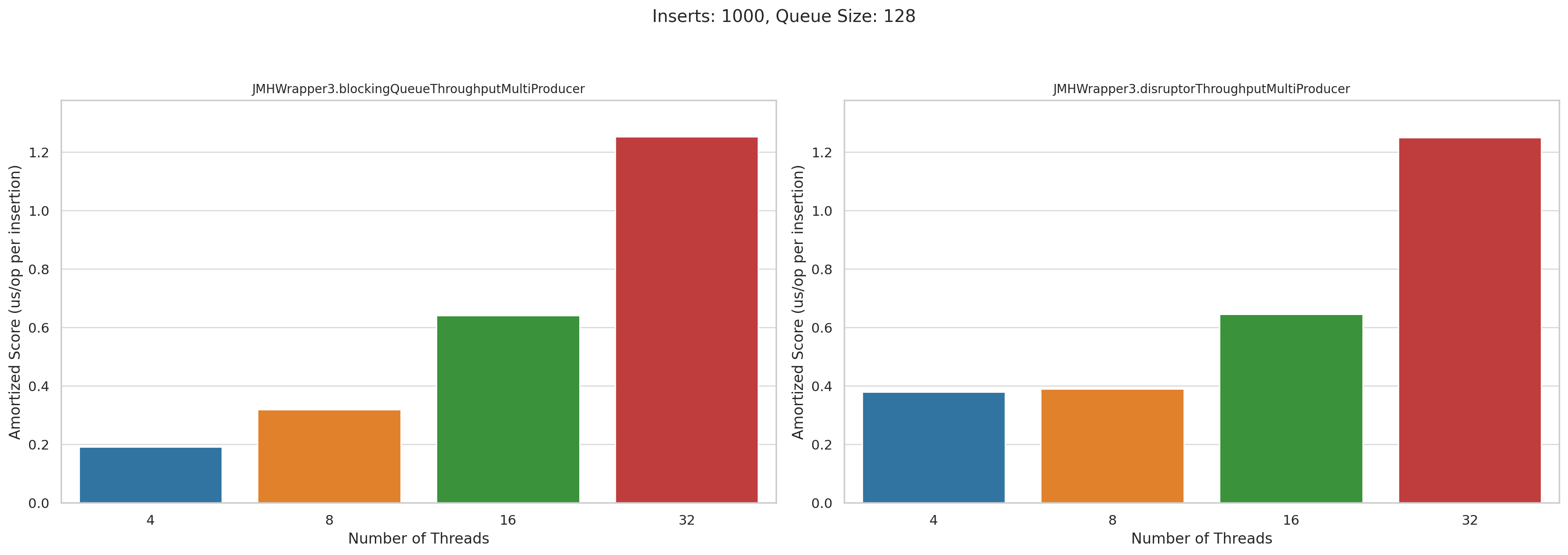
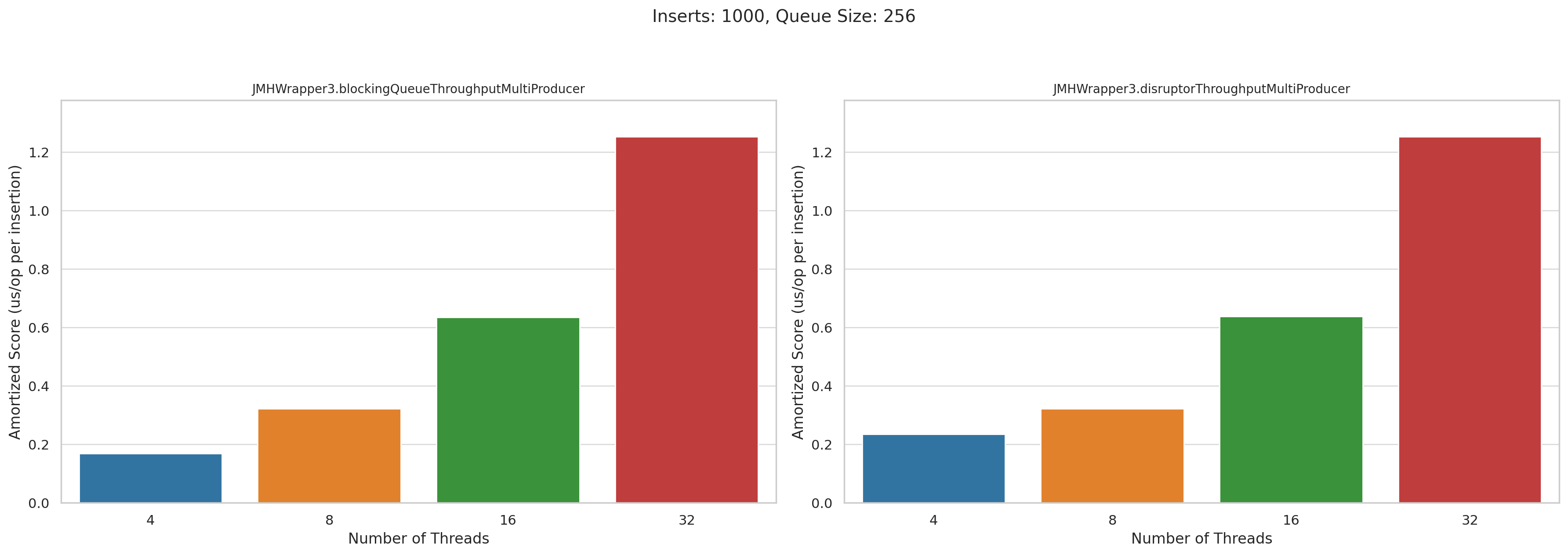
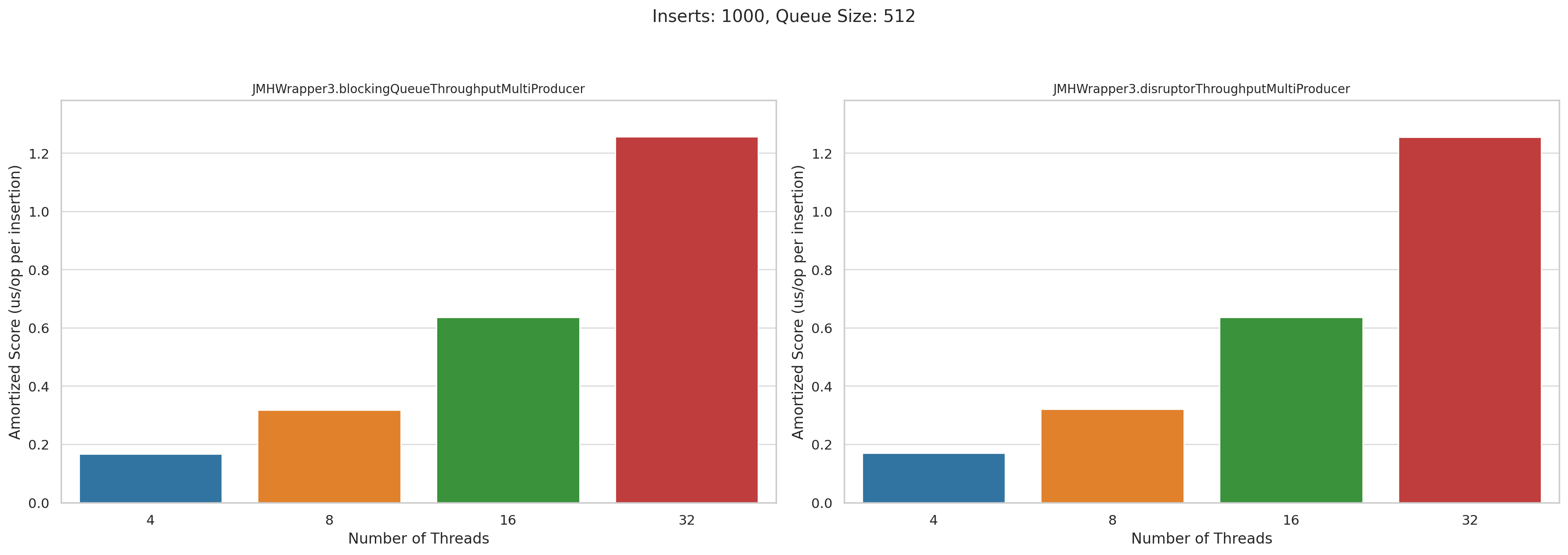
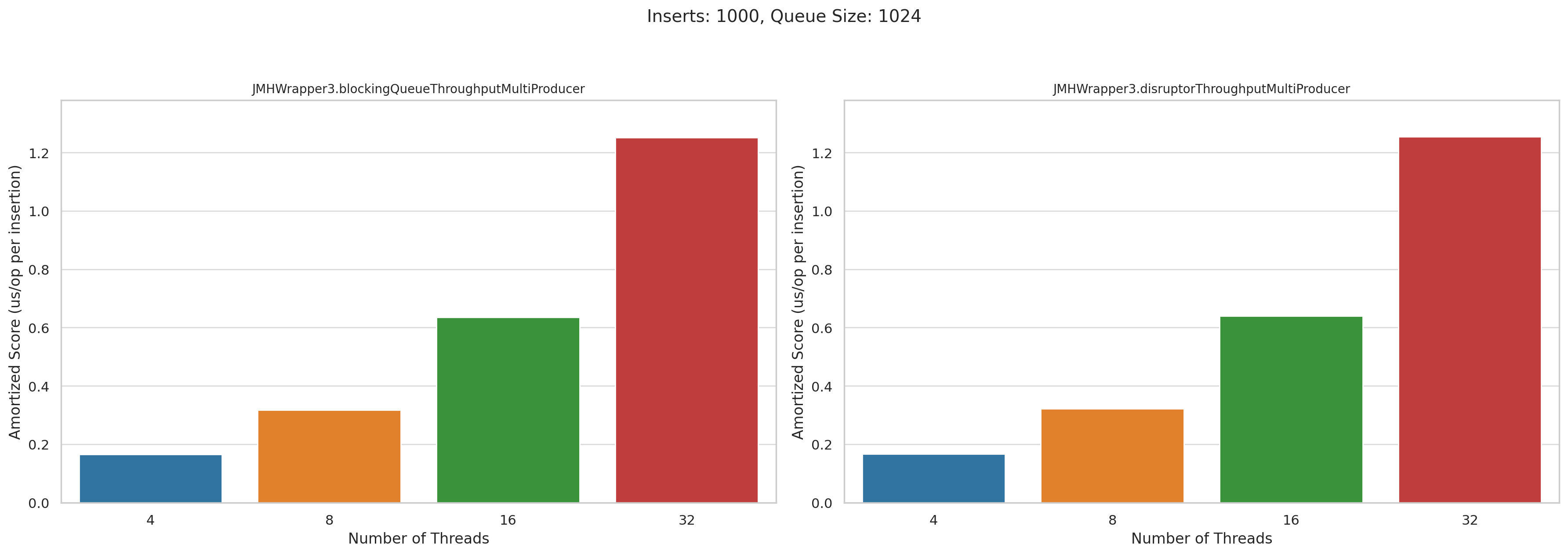
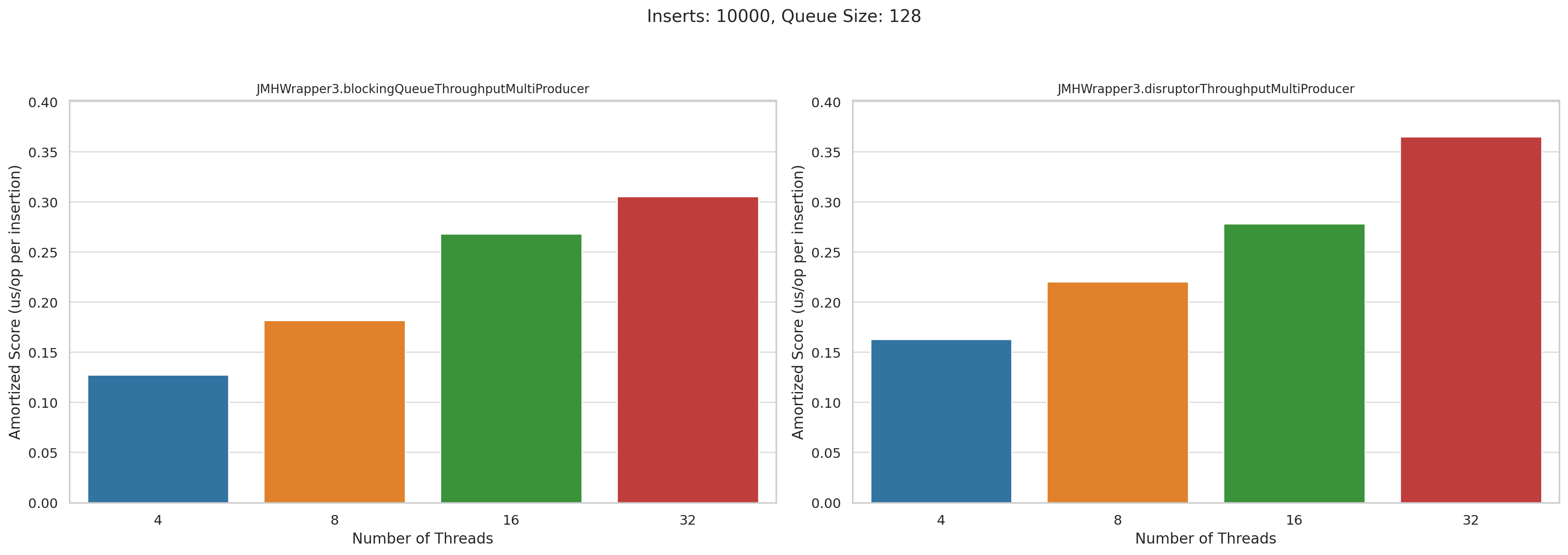
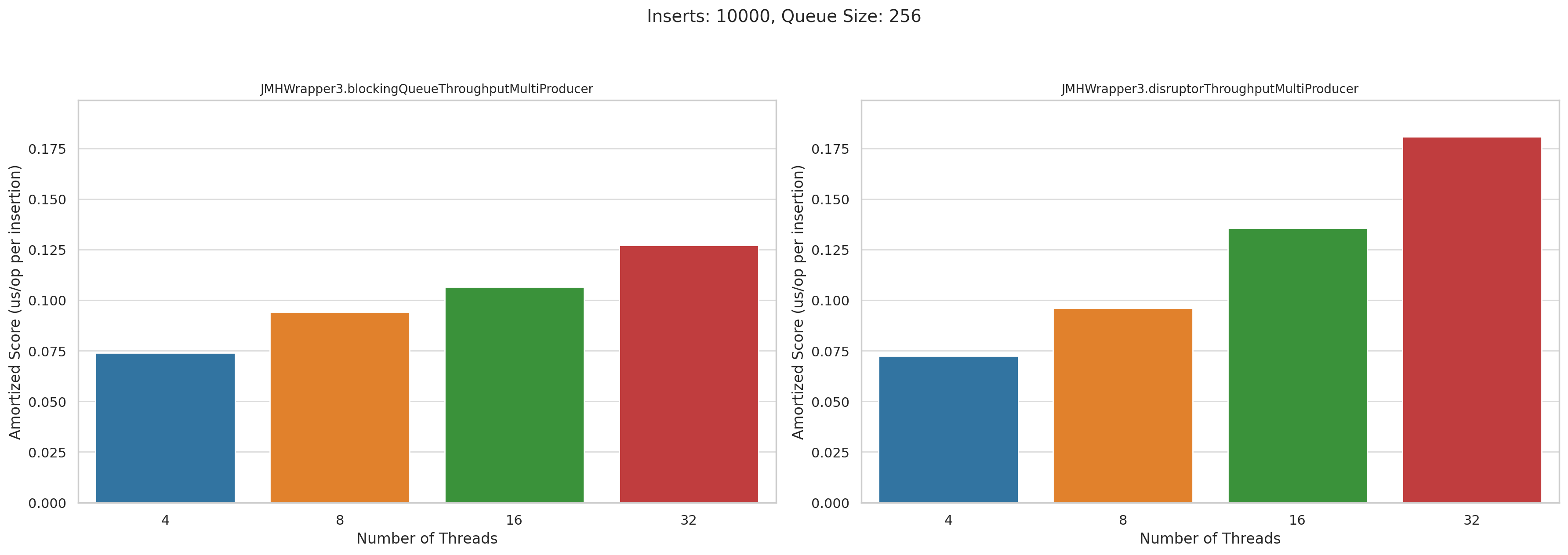
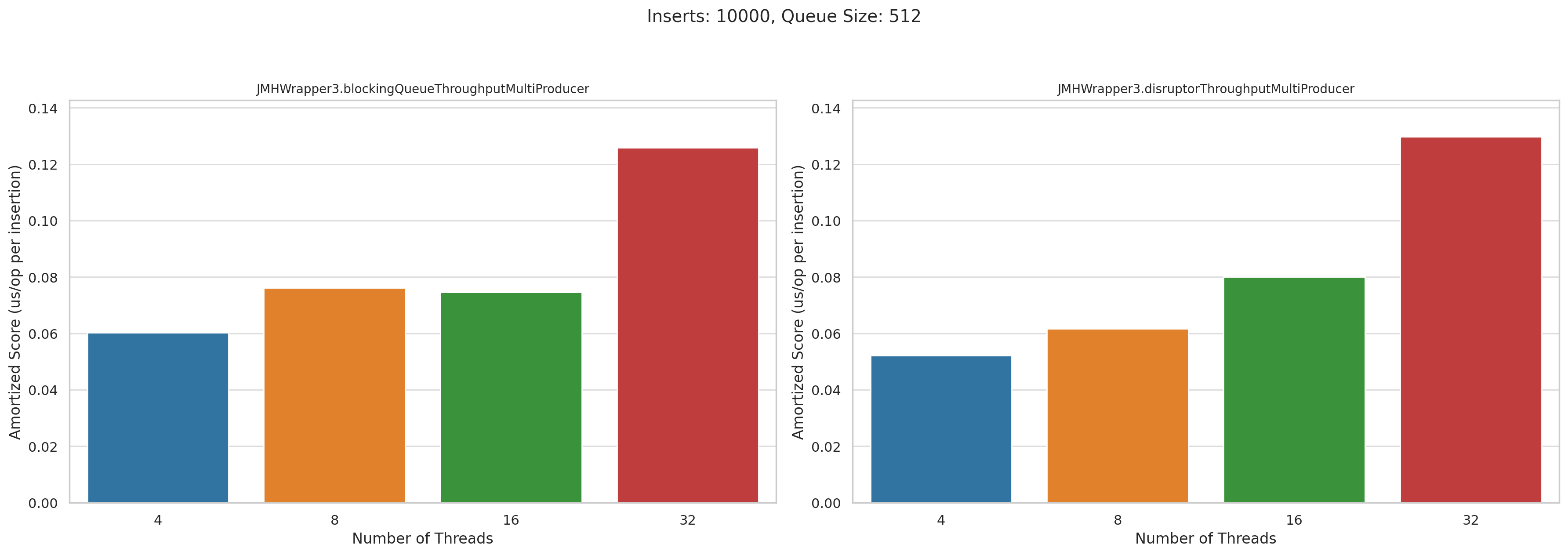
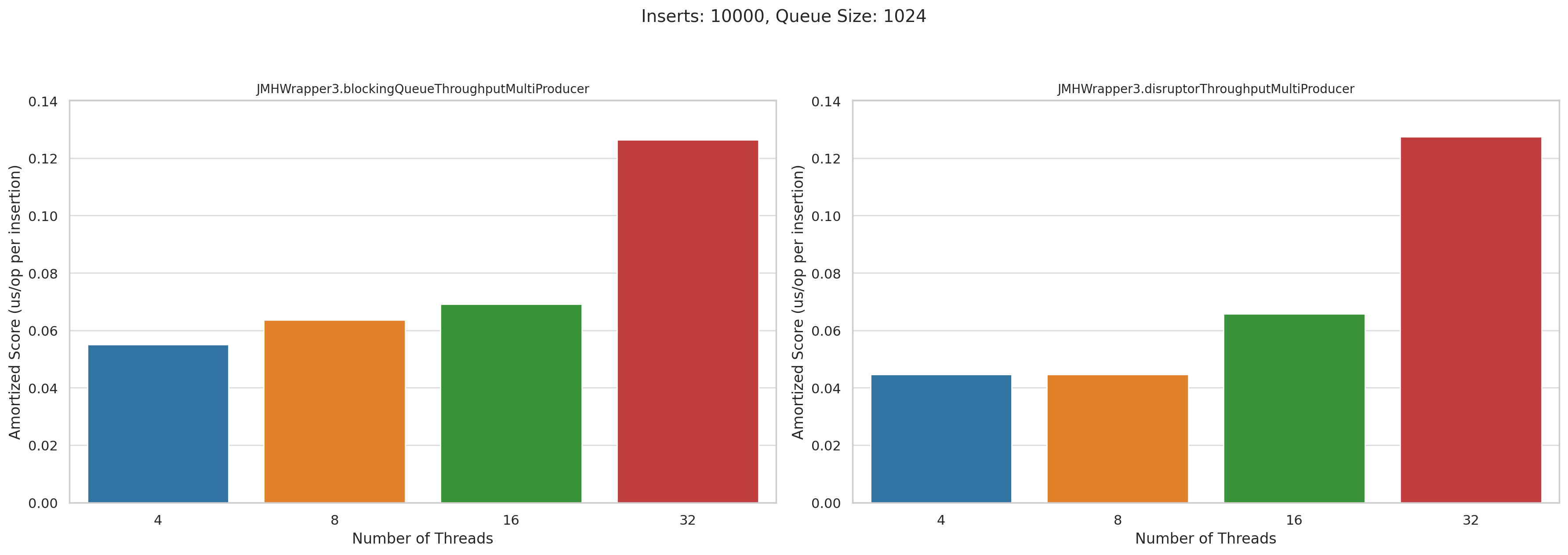
Pretty disappointing, honestly. I was really hoping that Disruptor would wipe the floor with BlockingQueue when we had high levels of concurrency, but they performed roughly the same.
Conclusion
These results were a bit disappointing, to a point where I suspect I did something wrong. I’ve heard Disruptor should do much better than BlockingQueue, so I think there’s probably a mistake in my tests.
I think if I do this in the future, I’m going to make much bigger batch sizes. The single-producer tests suggests that Disruptor might shine when you’re dealing with large quantities of data, and it’s possible that it can’t shine with batch sizes this small.
Anyway, I hope you got something out of this. As usual, if you see any mistakes, let me know and I’ll fix them or make a follow-up post.
Update
I wanted to test my hypothesis about bigger batches making a difference in Disruptor’s favor. I reran the same test as above, but with only 8 threads, a queue size of 1024, and batch size of ten million. CSV is here if you want to examine it. Here are the graphs:
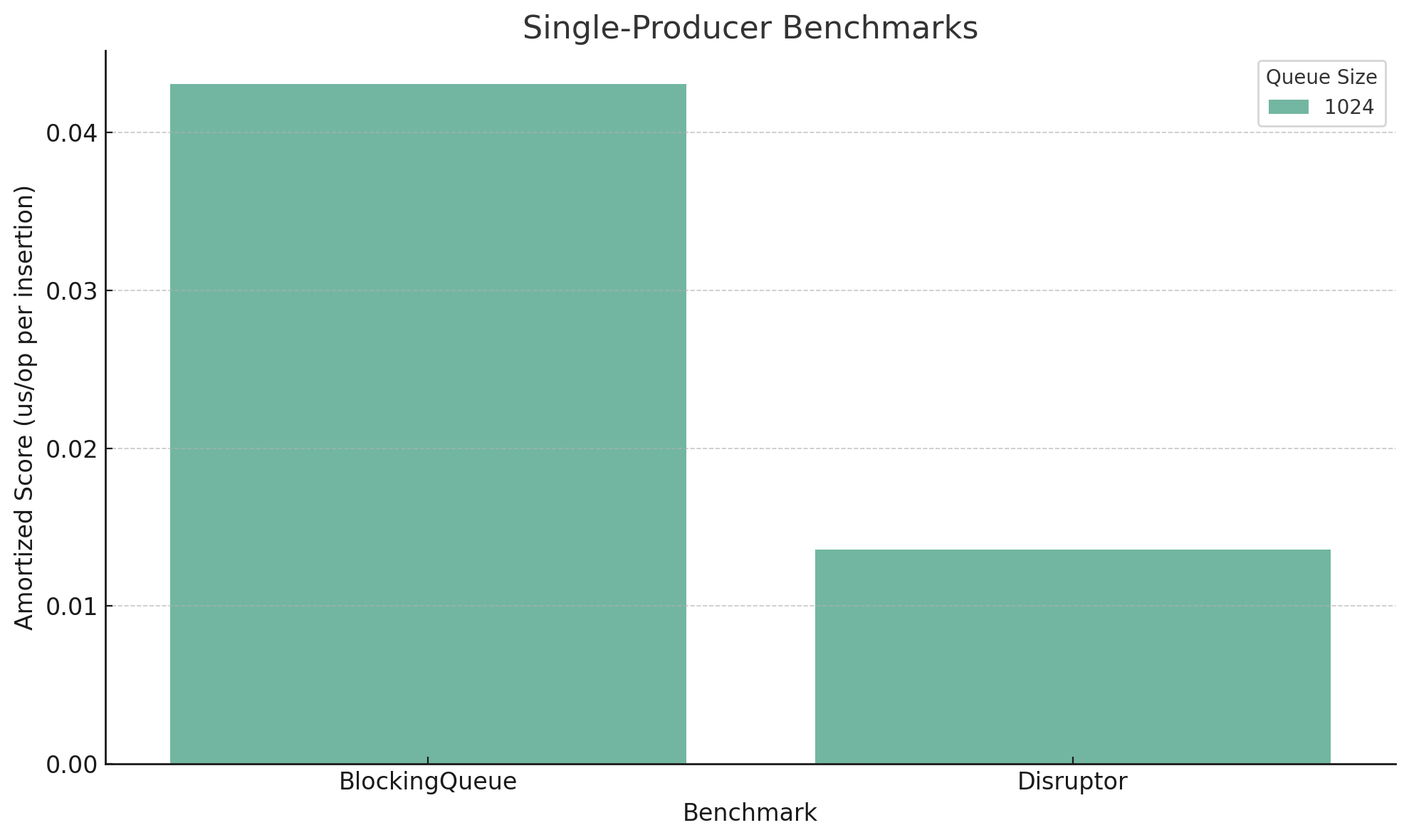
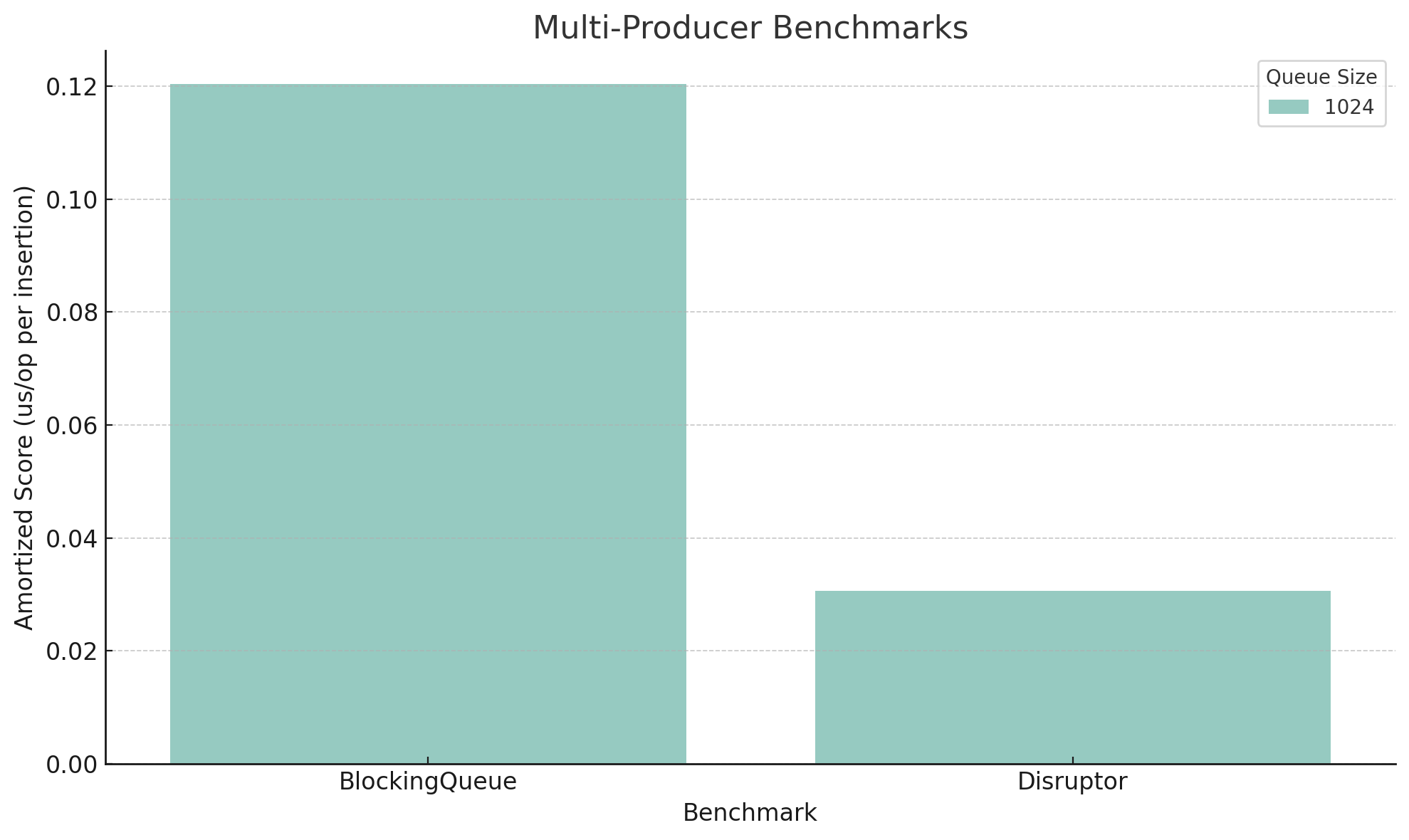
These confirm my hypothesis: Disruptor does much more favorably with large loads of data. As you can see in these charts, Disruptor is almost four times faster than BlockingQueue. I didn’t test this, but due to the fact that Disruptor doesn’t generate garbage, this might also mean you might be able get away with a bit less memory.
Pretty cool, now I understand why Disruptor is used in the trading world.
Update 2
I became curious if you could get away with less memory with Disruptor compared to BlockingQueue, so I updated the test above to set the numInsertions to $100,000,000$, set the threads to $8$, set the BlockingQueue size to 1024 and the Disruptor size to 512. Not exactly a huge difference, but still, it’s a buffer half the size. Anyway, here are the raw results:
Benchmark (numInsertions) (numThreads) Mode Cnt Score Error Units
JMHWrapper3.blockingQueueThroughputMultiProducer 100000000 8 avgt 25 7581954.067 ± 328236.807 us/op
JMHWrapper3.blockingQueueThroughputSingleProducer 100000000 8 avgt 25 5911906.769 ± 212562.285 us/op
JMHWrapper3.disruptorThroughputMultiProducer 100000000 8 avgt 25 2198090.340 ± 115452.790 us/op
JMHWrapper3.disruptorThroughputSingleProducer 100000000 8 avgt 25 1152971.196 ± 32262.975 us/op
And here’s the visualization:

Wow! Again, my hypothesis is confirmed that larger batch sizes are where Disruptor kicks the ass of BlockingQueue, but more importantly, it kicked BlockingQueue’s ass while using half the memory, and not generating any garbage in the process.
Disruptor is very cool, and I’ve only touched the surface of it.
Update 3
I couldn’t leave it alone.
I was curious how far we could go with the memory difference. I ran the tests above again, this time setting the size of BlockingQueue to $8192$, and keeping Disruptor at $512$. Running it again:
Benchmark (numInsertions) (numThreads) Mode Cnt Score Error Units
JMHWrapper3.blockingQueueThroughputMultiProducer 100000000 8 avgt 25 15151729.605 ± 1078587.464 us/op
JMHWrapper3.blockingQueueThroughputSingleProducer 100000000 8 avgt 25 8754937.698 ± 491486.528 us/op
JMHWrapper3.disruptorThroughputMultiProducer 100000000 8 avgt 25 3009995.574 ± 32276.494 us/op
JMHWrapper3.disruptorThroughputSingleProducer 100000000 8 avgt 25 1560987.924 ± 66095.430 us/op
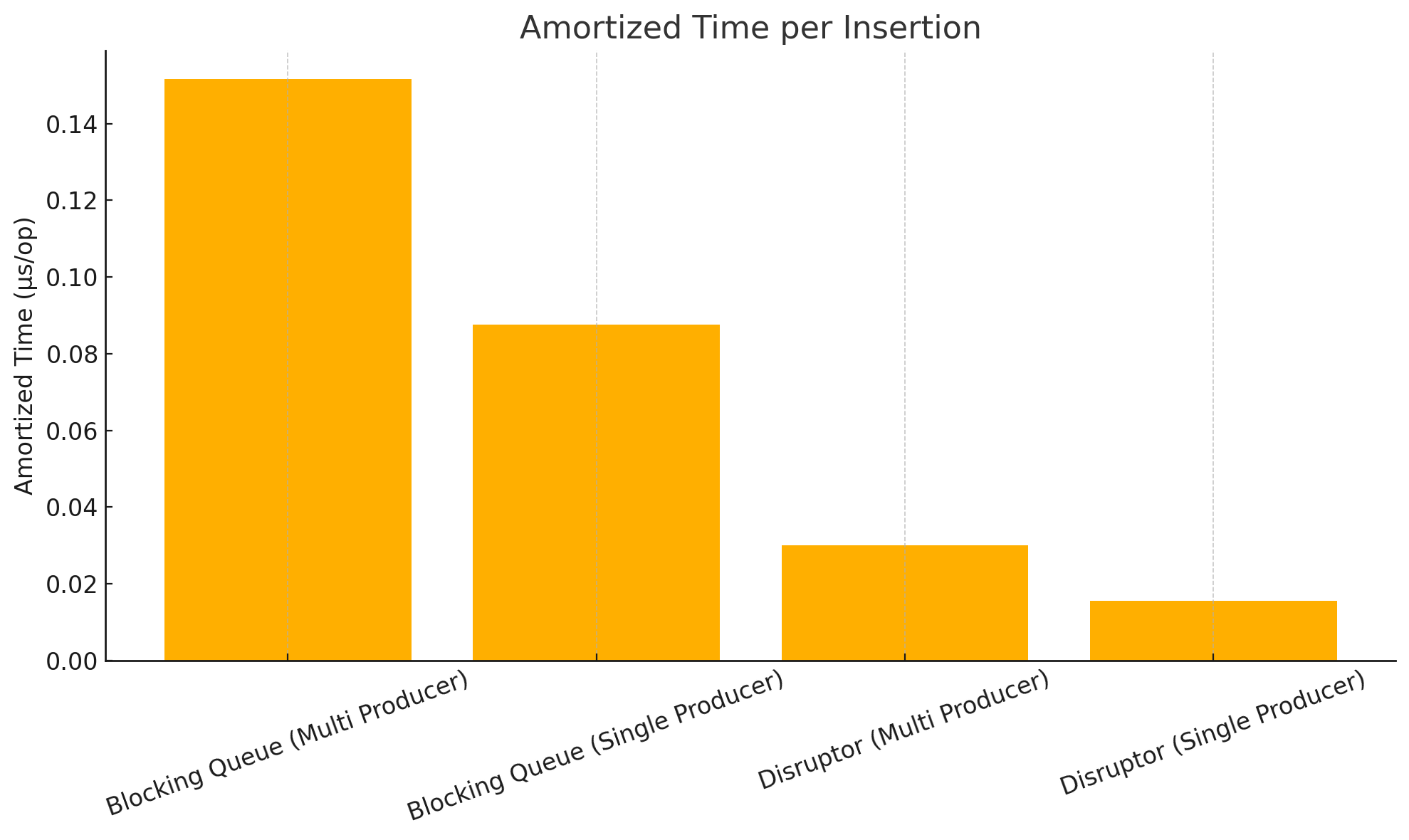
Interesting. So even though the BlockingQueue had sixteen times the memory, it was still considerably slower than Disruptor. I am even more impressed with this library now.
Computer used:
Operating System: NixOS Unstable
CPU: AMD Ryzen 9 6900HX with Radeon Graphics
RAM: 64 GB DDR5 4800 MT/s
JVM: jdk21 package in Nixpkgs