Trading Bot: Part 1
So in my ever-unemployed state, I have been trying to fill my time with lots of little projects in the vein hope of increasing my employability. To my continued disappointment, at least as of right now, no one wants to pay me to watch cartoons all day, much as I’ve tried, so instead I’m stuck working on programming projects.
For a long time, these projects typically involved me figuring out how to get something working on a server, and just playing around with whatever I set up. One of my favorite things that I built was a distributed video processing cluster to transcode my Blu-rays across six different nodes by abusing NFS and Docker Swarm.
As it stands, though, I’ve gotten to a point where I can do this kind of stuff so quickly that it’s not fun to just “set shit up” now. NixOS (thankfully) automates so much, and as a result, just building a cluster of something isn’t terribly interesting. It also doesn’t help that instead of a “cluster” of nodes, I just have one bigass used server now, which simplifies everything. Consequently, I’ve found that I have to work on harder problems instead of just getting my kicks in the setup phase.
This has also coincided with the fact that (until I was laid off) I have more or less hit a ceiling in how much compensation I can expect as a traditional software engineer. If my goal is to make more money, I’m left with two options:
- I can start a business.
- Get into the finance space.
Starting a business might be cool, but I am fundamentally a very disorganized person who also doesn’t have any interesting ideas with regard to making a business, not to mention that I have no interest in anything involved in making a business outside the technology aspect of it. I don’t want to fuck around getting funding and talking to investors and having to hire and fire people, and I don’t see that changing unless a small part of myself dies.
That leaves me trying to break into finance. I know absolutely nothing about money, and at first, glance it doesn’t seem like it would very interesting. However, it is extremely lucrative, and the high-frequency trading world ends up having a good number of interesting computer science problems to worry about.
I figured that cracking into the world of quantitative trading could be a fun project to kill some time, especially after I found out the Alpaca allows for paper trading, meaning that I couldn’t inadvertently get myself into debt.
Getting a stream of data
One thing that immediately triggered my inner cheapness was finding out that real-time feeds for stocks end up costing a fair bit of money, typically on the order of about $75 per month. This isn’t prohibitively expensive, but it’s more than I want to pay for a toy project.
Enter Cryptocurrency!
I generally think that cryptocurrency is pretty dumb. I am a victim of the idiotic Gemini Earn unregistered security stuff from last year, and I’ve come to learn that the entire premise of cryptocurrency is broadly stupid.
That said, I’m also not above using the publicly available cryptocurrency feeds to start playing with stuff, and Gemini is happy enough to provide such a websocket feed. According to this bit of documentation, we can get live market data to play with. Peaking at the websocket messages, they’ll look a bit like this:
wss://api.gemini.com/v1/marketdata/BTCUSD:
{"eventId":1682996448060923,"events":[{"delta":"0.05","price":"29819.95....
I think this has all the information that we care about, but you’ll find that every source has a radically different shape to their data. I plan on eventually having thousands of different tickers all chugging along simultaneously, and it would be extremely helpful if they all have the same shape. Additionally, we’ll most likely want to keep some level of historical data instead of peaking just at the price in real-time, so instead of working with Gemini’s data stream directly, I think we’ll need to buffer the data somewhere.
Storing the data
The amount of potential data that you can work with in the quantitative trading world is nearly endless and is limited almost exclusively by how much you’re willing to store and how up-to-date your stock ticker data is.
Some people seem to have had luck using vanilla databases like PostgreSQL or MariaDB. These will work, and give a lot of flexibility in regards to how you query. Additionally, they’re extremely well-supports and safe databases.
However, vanilla SQL databases have a few inherent drawbacks. They can be difficult to scale and shard, but perhaps more importantly, they can be slow to query, even for relatively cheap things like key lookups, especially when we’re dealing with tables that can be multiple gigabytes. This isn’t a dig on SQL, it’s not unnecessarily slow; ACID compliance requires a lot of very strict constraints, and these come at a performance cost. These constraints and guarantees make SQL an extremely resilient choice for data, but not the fastest.
This brings us to the land of NoSQL, like MongoDB, CouchDB, and Cassandra. These databases are extremely well optimized for key lookups and for dealing with large quantities of data, while also giving the ability to do advanced queries if necessary. Cassandra in particular has become almost synonymous with “big data”, and it’s not hard to make it deal a thousand nodes if necessary.
The implementation details of these databases vary a lot, but they generally focus broadly on ensuring that the database is always available, and not necessarily consistent between nodes.
Honestly, when I initially began this project, I started by using Cassandra, I started asking myself some questions just as I was starting to write a script to clean up stale data: do I actually need a database if this stuff is temporary anyway? Also, instead of periodically querying data, wouldn’t it be better to just have this be some kind of real-time feed?
If you’re asking yourself these kinds of questions, there’s a good chance that Apache Kafka might be a better fit for you than a database.
What is Apache Kafka?
Kafka is an open-source publish-subscribe bus. Data is inserted into buckets called “topics”, and programs can consume data from these topics as they come in.
Calling it a pub-sub bus by no means undersells it because Kafka has one killer feature that its competitors don’t: Kafka is disk-based. Being disk-based affords Kafka a number of advantages. First, and probably most importantly, it allows your data to survive a crash. The data is written to the disk after all, so even if the computer crashes it should still exist upon a reboot. Second, Kafka since Kafka buffers everything through the disk, it’s not nearly as confined by the size of data as other solutions. Multi-terabyte disks are pretty cheap nowadays, much cheaper than the equivalent amount of RAM, and as such Kafka has developed a reputation of being something that can handle any amount of data being thrown at it.
You might think that Kafka being disk based would imply that it’s slow, but due to a lot of clever engineering by the Kafka team, even this isn’t true. Kafka tends to perform just as well as other pubsub solutions out there, and consequently it has grown extremely popular in a fairly short amount of time.
Another killer feature of Apache Kafka is its ordering and partitioning guarantees. Due to how the data is divided into partitions, it’s fairly straightforward to process data in parallel across multiple nodes. Additionally, for things that we want to ensure are done in the correct order, we can utilize partition keys to ensure that they’re processed in a first-in-first-out fashion. There’s some more cleverness we can do with these keys but I’ll save that for part 2.
We can achieve parallelism across nodes by utilizing “consumer groups”, which is basically a fancy way of saying “service ID”. If we have two instances of a program with the service ID “stock-consumer”, consuming from a topic with four partitions, each node will focus on the data from two partitions each.
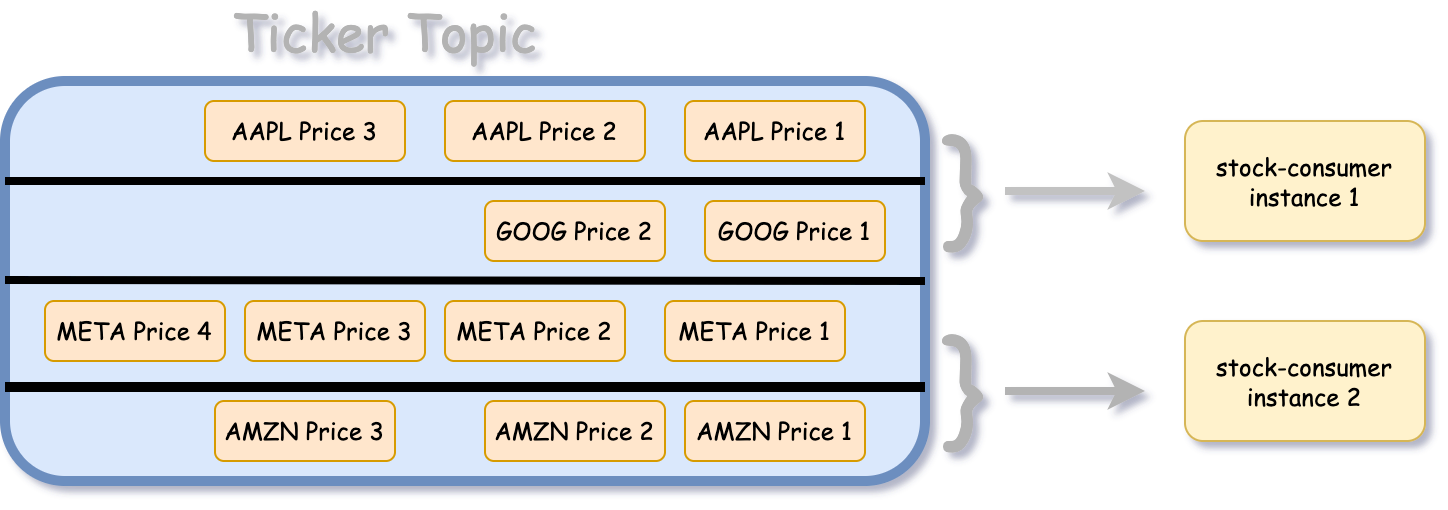
Kafka also has the advantage of allowing us to set our own retention time for the data. For now, I only want to concern myself with data that’s less than a week old, so I can set the retention time to 604,800,000 milliseconds. Kafka will automatically clean up data older than that. This isn’t too hard to do yourself even with a regular database, but it’s one less service that we have to worry about, and due to how much funding Kafka has, is probably going to be done correctly.
Event Sourcing
This pattern has gotten a lot of traction in the last few years and has various buzzwords associated with it, probably most commonly referred to as “event sourcing”, and its appeal should be obvious: by decoupling the producer and consumer, we allow for a lot of independence, and as such we can easily scale both in performance and effort.
For example; if our consumer crashes, this theoretically doesn’t need to completely stop progress. The producer can still keep chugging along, pushing messages into our bus, and consumption can continue as the consumer restarts.
Another advantage is that there’s no requirement for the producer(s) or consumer(s) to be the same language. It might make sense to use an easy-but-slow language like Python for our producer, but then use a faster language like Go for our consumption to do some number crunching.
Data Serialization
The last part we have to worry about (for now) is how we’re going to store the data in Kafka.
There appears to be a more or less even divide on the best format used to encode messages for Kafka. You have the “slow but easy” side taking to the camp of JSON, and you have the “fast and verbose” side using Avro.
I’m not terribly smart, so I decided to use neither of these and instead opted for my favorite binary serialization format: msgpack.
Msgpack (or MessagePack) is a binary serialization format that’s meant to be “JSON but with more features and binary encoded”. While it’s certainly an underdog in this field, it actually performs better than enterprise-preferred solutions like Protocol Buffers, while being substantially easier to use.
Its ease of use is the primary reason that I find myself repeatedly coming back to Msgpack; unlike Protocol Buffers which require a lot of evil code generation and a rigid structure, Msgpack is happy being flexible and simple. No matter what language I seem to throw at it, msgpack just keeps chugging along.
Msgpack also has the advantage of supporting substantially more data types than vanilla JSON; nearly anything that can be serialized will be serialized, and it plays much nicer with things like dates and symbol types. This is especially useful when working across different languages, which might have extremely different encodings for different types; this is more or less transparent to us and that makes me happy.
Writing the Inserter
Now that we know we’re going to use Kafka, we can actually start writing some basic code, even if we’re not 100% sure of our strategy right now. I’m using Clojure for this for no particular reason other than “I like it”.
We need to listen on some websockets. There are a number of libraries that can do this in Clojure (or Java), and the first one I tried that seemed to work was hato. The code for consuming from a websocket is pretty straightforward:
(defn start-websocket-client [url f]
(let [ws @(ws/websocket url
{:on-message f
:on-close (fn [ws status reason]
(println "WebSocket closed!")
(start-websocket-client url f))})]))
Our function takes in a handler function that we pass along to the :on-message callback.
The :on-close thing exists as a bit of a failsafe. Sometimes these websockets will disconnect for some reason, but the program will keep running and we won’t be inserting new data. When that happens, I want to catch it and start the consumption again to minimize lost data. It’s a big hackey, but it does work.
We should probably define a function to handle messages now. This can be easily done easily in five steps:
- Deserialize the JSON.
- Extract the fields we care about.
- Shape the data how we want.
- Serialize the data with msgpack.
- Put the serialize message into Kafka.
Let’s first define a generic function to insert stuff into Kafka, which can be done with a very basic wrapper around the vanilla Java Kafka producer.
(defn insert-into-kafka [prod topic pkey message]
(.send prod (ProducerRecord. topic pkey message)))
Now we can build our message handling logic.
(defn handle-crypto-message [prod topic sym _ws msg _last?]
(let [
des-msg (->> msg str json/read-str)
out-struc {
:sym sym
:ts (get des-msg "timestampms")
:price (-> des-msg
(get-in ["events" 0 "price"])
bigdec)}
out-bytes (msg/pack out-struc) ]
(insert-into-kafka prod topic sym out-bytes)))
As you can see, we are going to partition on the ticker symbol just because that’s an order I’d like to preserve.
We make a Clojure map that has the ticker symbol. This is arguably unnecessary because the ticker is also the partition key, which we retain access to, but it also doesn’t take a lot of extra storage and it can be handy to have access to it when processing.
Something that might seem a bit weird is the invocation of bigdec. This is also probably not strictly necessary, but it’s generally considered a no-no to store money in a normal floating point format, due to the rounding inherent to how CPUs handle floating point arithmetic. Clojure’s bigdec is encoded at a higher level than than the normal IEEE encoding, which does have a small performance penalty, but is probably still fast enough for nearly anything and doesn’t suffer from truncation.
We can now build a quality-of-life helper for our consumption:
(defn gemini-sock-stream [ticker prod topic]
(start-websocket-client (str "wss://api.gemini.com/v1/marketdata/" ticker "USD") (partial handle-crypto-message prod topic ticker)))
Finally, we need to kick off the work. I think it’s fine to do this in our main function:
(defn -main
"I don't do a whole lot ... yet."
[& args]
(let [
broker "MY_BROKER_URL"
topic "tickers"
prod (create-kafka-producer broker)
tickers ["BTC" "ETH" "LTC" "DOGE"]
]
(doseq [ticker tickers]
(gemini-sock-stream ticker prod topic))
(Thread/sleep Long/MAX_VALUE)
))
For now, we’re listening on four separate websocket streams running concurrently: BTC, ETH, LTC, and DOGE. Since the websocket functions don’t block, we have to manually do that ourselves with a Thread/sleep.
If we spin this sucker up, stuff will be inserted into our Kafka topic called tickers.
Conclusion
And there we have it! Step 1 of many, many steps towards making a profitable trading bot. Tune in next time where we talk about the best ways to consume from this topic.